AI Writing Systems: From Draft to Publish — Reliable Prompt Engineering & Production Workflows
AI Writing Systems: From Draft to Publish matter because generative models can transform content production speed and scale, but only when organized into reliable, repeatable systems with clear QA and observability. This article explains what to design (system boundaries, retrieval, evaluation), how to design prompts for production, a concrete step-by-step workflow you can implement, and the failure modes and quality-control steps required to operate at editorial scale. Key engineering references and tools are cited throughout so you can follow original documentation and operational patterns. (help.openai.com)
Core principles behind the workflow
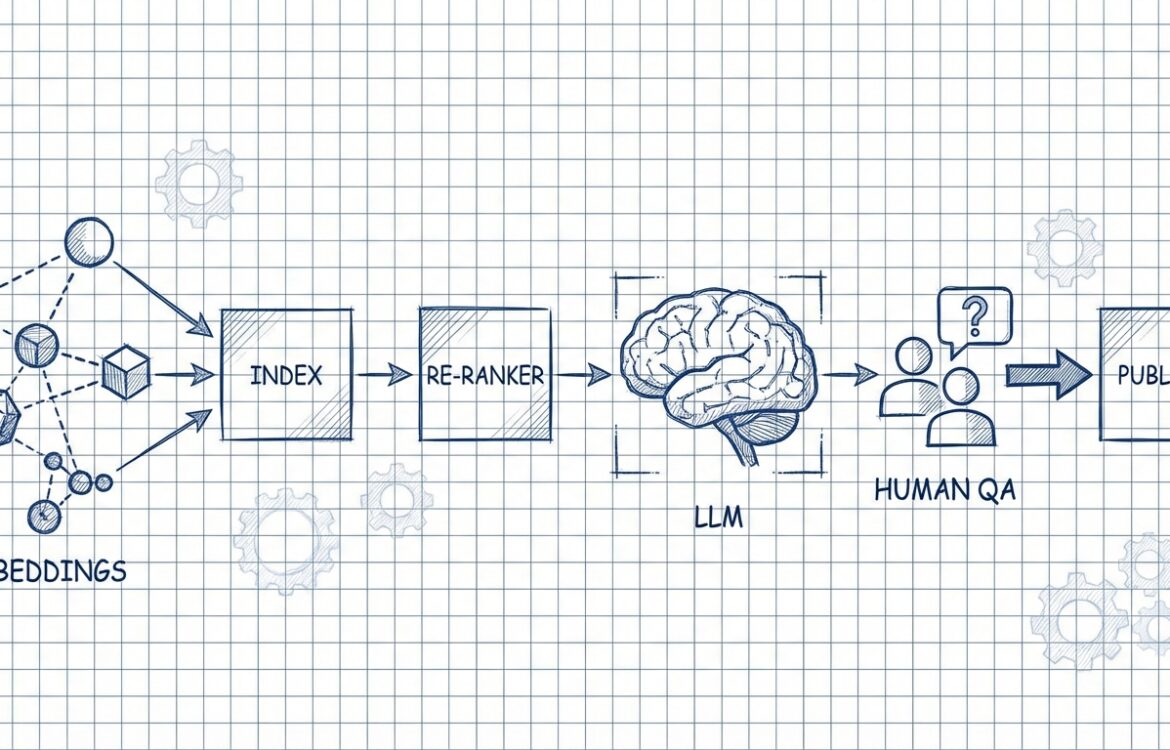
Designing an AI writing system for production is an exercise in systems engineering: isolate components, define contracts, measure performance, and enforce human accountability. At minimum, separate these layers: prompt and role definitions, retrieval (if used), model invocation and parameterization, post-processing/filters, evaluation, and the human-in-the-loop approval pipeline. Keeping these layers modular lets you swap retrievers, vector stores, or models without rewriting business logic. (vdf.ai)
- Define explicit success criteria: Success must be measurable (factual accuracy, adherence to style guide, SEO metrics, publication latency). Establish evaluation datasets and acceptance thresholds before you iterate on prompts. (docs.anthropic.com)
- Make prompts deterministic building blocks: Treat prompts as versioned code artifacts with tests and rollout controls rather than informal notes. Use a prompt registry or store so prompts are auditable and can be A/B tested. (promptlayer.com)
- Ground outputs with retrieval when accuracy matters: For factual claims, use retrieval-augmented generation (RAG) and inject explicit instructions that require citations or source-limited answers. The retrieval layer is often the single biggest determinant of factual reliability. (kairntech.com)
- Design for observability and regression testing: Version prompts and models, run automated evals and historical backtests on saved inputs, and monitor production drift. Frameworks like OpenAI Evals or similar registries provide templates to codify these checks. (github.com)
- Human accountability and editorial control: Put a named editor in the loop for any public-facing content; log who approved what and why. Editorial checks should include factual verification, brand voice, copyright checks, and legal safety. (wiley.com)
Recommended prompt structure
Prompts for production should be structured, composable, and explicit about constraints. The recommended template below is intentionally modular — separate system-level instructions, context (retrieved evidence), task description, examples, and the required output format. This reduces ambiguity and improves repeatability. (help.openai.com)
- System / role block — one short paragraph describing the model’s role and high-level rules (tone, safety constraints, when to abstain). Example: “You are a fact-first editorial assistant. If you cannot verify a claim, reply ‘INSUFFICIENT_EVIDENCE’.” (docs.anthropic.com)
- Context block — clearly delimited retrieved content or brief author notes. Always mark the boundary (e.g., “–BEGIN SOURCES–” and “–END SOURCES–“) so the model treats them as evidence only. When using RAG, include metadata (source, date) near each snippet, but keep that metadata out of the visible text sent to readers. (vdf.ai)
- Instruction block — precise action (what to write), constraints (word count, audience level), and required safety checks (e.g., “verify any statistic; if unverifiable, remove it”). Use bullet lists for multi-part instructions. (help.openai.com)
- Examples/format block (optional but recommended) — provide 1–3 short examples showing desired structure and tone. Prefill parts of the output (a heading or outline) when you want consistent format. (docs.anthropic.com)
- Output constraints — machine-friendly tokens to indicate success/failure and explicit JSON or markup schema if downstream tooling expects structured output. Require the model to return a confidence flag or evidence pointers when appropriate. (github.com)
Example minimal prompt skeleton (conceptual): supply the role, then the context, then the instruction to produce an outline of up to 8 headings, each with a one-sentence summary; require a “sources” list referencing context items. Keep token budgets in mind and truncate or summarize long context snippets. (tensorblue.com)
Example workflow (step-by-step)
The workflow below is a practical end-to-end pipeline that takes a topic from initial research to published copy while preserving auditability and editorial responsibility.
- Topic selection & brief
Author or editor creates a content brief with target audience, primary keyword, scope, desired voice, and a list of non-negotiables (legal, compliance, safety). Store the brief in the content management system as the single source of truth. (marketingadvice.ai)
- Research collection & corpus curation
Fetch primary source documents and curated references. Preprocess and chunk documents for retrieval (preserve semantic boundaries and metadata like date and source). Run a light quality filter to exclude low-credibility sources. For sensitive or regulated content, restrict retrieval to approved corpora. (kairntech.com)
- Initial draft generation (Draft stage)
Call the model with a prompt that includes the brief and a short selection of retrieved evidence. Use explicit instructions to format the draft and to surface any unverifiable claims as placeholders. Save the prompt version, model ID, temperature, and the full request/response record for reproducibility. (promptlayer.com)
- Automated checks (pre-edit QA)
Run a sequence of automated validators: grammatical/consistency lint, citation presence checker, duplicate-content/plagiarism scan, factual verification routines (e.g., run named-entity facts through knowledge APIs or a second model tasked with verification). Flag items that require human review. Use model-based or rules-based detectors to surface hallucinations. (emergentmind.com)
- Human editorial review (Edit stage)
Editors see the draft in a review UI with context: original brief, retrieved sources, and automated check results. Editors correct factual errors, add original insights, and confirm sources. For high-risk content, require a subject-matter expert sign-off. Record reviewer ID and timestamp. (wiley.com)
- Post-edit validation (pre-publish QA)
Re-run automated validators and a final model-based consistency check. Run a regression test suite that replays a sample of historical inputs to ensure prompt or model updates didn’t introduce new errors. If any validators fail, route back to the editor with a prioritized bug list. (github.com)
- Publish & observability
Publish into the CMS with metadata tracking: prompt version, model version, retrieval snapshot, editor approval, and publish timestamp. Monitor key signals post-publish (user feedback, bounce rates, factual challenge reports) and capture examples for continuous evaluation. Set thresholds that trigger rollback or manual audit. (ciberspring.com)
- Continuous evaluation and iteration
Maintain an eval registry (unit tests for prompts and models) and schedule periodic re-evaluation. Use production telemetry to seed new regression suites and to drive prompt improvements or retraining decisions. Frameworks such as OpenAI Evals or custom model-graded tests allow you to codify acceptance criteria and automate checks. (github.com)
Quality control and failure modes
Quality control must be layered: automated, model-based, and human checks. Below are the most common failure modes you will see in practice, how to detect them, and recommended mitigations.
- Hallucinations (plausible-sounding false facts)
Detection: cross-check claims against retrieved evidence; run a dedicated model-based verifier; monitor upstream user reports and factual challenge flags. Mitigation: tighten prompt constraints (require “cite source id”), use RAG with high-quality corpora, and add correction loops (agentic review or multi-agent verification). Recent literature and surveys emphasize multi-layer mitigation combining retrieval, verification, and human review. (mdpi.com)
- Context drift and stale sources
Detection: date-mismatch checks on retrieved content and a sudden increase in user corrections. Mitigation: include source dates in retrieval metadata, set TTLs for documents, re-embed and re-index on schedule, and apply hard source filters for time-sensitive topics. (vdf.ai)
- Style and brand inconsistency
Detection: editorial reviews and automated style linters scoring tone and terminology use. Mitigation: embed a brand voice block in the system prompt and enforce via automated checks; keep a living brand voice document as a canonical prompt snippet. Human oversight remains necessary to preserve nuance. (marketingadvice.ai)
- Regression after prompt or model change
Detection: failing regression tests or sudden production metric regressions after deployment. Mitigation: run backtests against stored historical inputs before full rollout, use canary or A/B deployments, and keep the ability to rollback to the previous prompt or model. Prompt versioning and eval pipelines help prevent accidental regressions. (promptlayer.com)
- Privacy and sensitive-data leakage
Detection: automated scanners for PII in outputs and audit logs, policy violation alerts. Mitigation: scrub inputs/outputs for sensitive fields, use private on-prem or enterprise models for regulated data, and restrict prompt editing to authorized personnel. Document retention policies for auditability. (wiley.com)
Operational QA checklist (concise): maintain prompt and model versioning, store full request/response logs, schedule automated eval runs, keep a named human approver for each published item, and enforce source verification for claims. Use an eval framework to codify acceptance criteria and to automate continuous checks. (github.com)
FAQ
What is meant by AI Writing Systems: From Draft to Publish and why use it?
“AI Writing Systems: From Draft to Publish” describes an engineered pipeline that combines prompts, retrieval, model calls, automated checks, and human editorial control to produce publishable content reliably. The goal is to scale content creation while preserving accuracy, brand voice, and legal compliance. Key tools and practices include RAG for grounding, prompt versioning, and scheduled evaluations. (solutionsarchitecture.medium.com)
How should I version prompts and models in production?
Treat prompts like application code: store them in a registry or source-controlled system, tag versions, and attach metadata (who changed it, why, and what tests pass). Use automated evals and historical backtests on each change and deploy via progressive rollouts (canary/A-B). Commercial prompt-management platforms provide built-in versioning and regression tooling. (promptlayer.com)
How do I reduce hallucinations in long-form articles?
Use retrieval-augmented generation with carefully curated sources, enforce prompt instructions that require the model to cite only retrieved sources, add verification steps (secondary model or rule checks), and require human fact-checks for claims. Literature and industry guides recommend layered mitigation (retrieval + verification + editorial review) for high-stakes content. (kairntech.com)
What automated evaluations should I run before publishing?
At minimum: plagiarism detection, factual-claim coverage checks (do claims map to retrieved sources), style/brand compliance linting, and a model-graded relevance/accuracy score using an eval framework. Maintain a registry of unit-like tests (evals) that run on prompt or model changes. (github.com)
When is fine-tuning or retrieval better than prompt engineering?
Start with prompt engineering and retrieval — they are faster and lower-cost to iterate. If you need deterministic behavior across many calls, or want to bake domain knowledge into the model consistently and at lower per-call latency, consider fine-tuning or building a domain-specialized model. Evaluate cost, latency, and maintainability trade-offs before committing to fine-tuning. (docs.anthropic.com)
Putting these practices into place will not eliminate all errors, but they create a reliable, auditable path from draft to publish that reduces risk and preserves editorial quality. The next steps are practical: choose an eval framework, create a prompt registry, design a small RAG corpus for your domain, and pilot the workflow with a named editor in the loop. Record results, iterate, and expand the automation surface as confidence grows. (github.com)
I write about turning AI from a fragile experiment into something teams can rely on every day. My focus is on prompt engineering, agentic workflows, and production systems—showing how to design, test, version, and scale AI work so it stays consistent, repeatable, and useful in real businesses.