RAG in Production: A Practical Engineering Guide — Architecture, Trade-offs, and Operational Checklist
Scope and assumptions: this guide targets software and AI engineers responsible for building and operating Retrieval-Augmented Generation (RAG) systems in production. It focuses on concrete engineering decisions—retrieval and indexing, vector stores, model selection and orchestration, deployment patterns, and security trade-offs—rather than research-forward model architectures. Where statements rely on external guidance or empirical results, I cite sources. If evidence is absent or uncertain, I note it explicitly. This article uses “RAG in Production” as the core topic and assumes you already have working prototypes of embeddings and a generative model. Important background on the RAG algorithm is established in the original RAG paper. (arxiv.org)
Conceptual overview of RAG in Production
Retrieval-Augmented Generation (RAG) combines a parametric LLM that generates text with a non-parametric retrieval component that supplies relevant documents or passages at inference time. The retrieval step reduces dependence on model parameter memorization, enables updatable knowledge, and supports provenance when the retriever returns source identifiers. The original RAG formulation (retriever + seq2seq generator) showed improved performance on knowledge-intensive tasks by conditioning generation on externally retrieved passages. (arxiv.org)
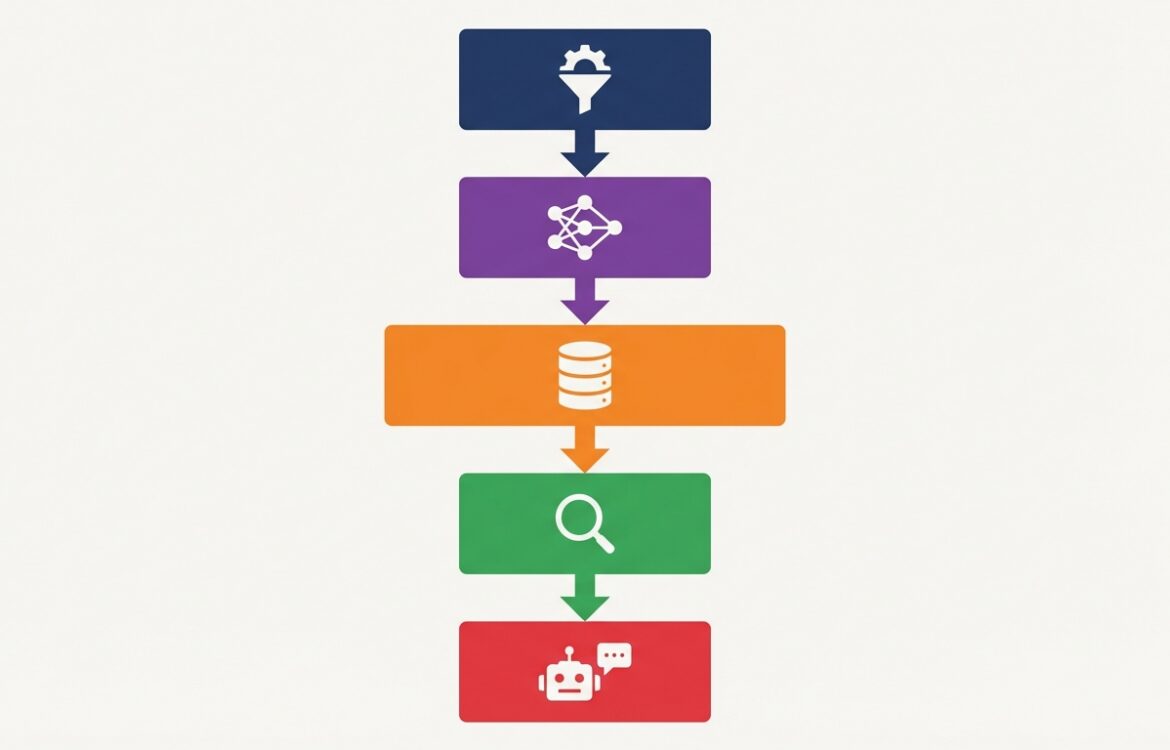
In production, a RAG system typically splits into two pipelines: an offline indexing pipeline that ingests and preprocesses documents, computes embeddings, and stores vectors and metadata into a vector database; and an online query pipeline that (1) converts the user query to an embedding or features, (2) issues a similarity search against the vector store, (3) applies filtering, reranking or extractive steps, and (4) conditions the generative model on the selected passages to produce the final answer. Engineering blogs and deployment guides emphasize separation of indexing and query workloads because their latency, scalability, and resource profiles differ. (haystack.deepset.ai)
How it works (step-by-step)
Below is a practical step-by-step execution path for a production RAG pipeline.
-
Data ingestion and preprocessing: canonicalize file types, remove boilerplate, split long documents into chunks with stable identifiers, and attach provenance metadata (source URL, document id, timestamps). Referencing and storing provenance at ingestion is essential for audits and user-facing citations. (deepset.ai)
-
Chunking and embedding: choose chunk size based on semantic coherence and the retriever model’s context window; compute embeddings using a production-grade embedding model and normalize them consistently. Chunk-granularity affects recall and cost—short chunks can increase recall but raise index size and latency. (haystack.deepset.ai)
-
Indexing: write vectors plus metadata into a vector database. Options include managed services (Pinecone) for fast time-to-market or self-hosted systems (Milvus, Weaviate) for on-premises control and data residency. Each option has trade-offs in operational burden, latency guarantees, and cost. Plan for sharding, replication, and backup during index creation. (antalyze.ai)
-
Retriever composition: use a single retriever (dense vector), a keyword-based retriever, or a hybrid retrieval stack (sparse + dense). Hybrid systems often improve precision by combining fast keyword filters with semantic vectors for relevance. Production frameworks support hybrid retrieval for cases requiring exact matches plus semantic similarity. (haystack.deepset.ai)
-
Reranking and filtering: after the initial k-nearest neighbors, apply a reranker (cross-encoder or lightweight scoring) to reorder results based on query-passage interaction, then apply deterministic filters for access control, date bounds, or PII rules. Reranking increases quality at CPU/GPU cost and latency trade-offs. (haystack.deepset.ai)
-
Context assembly and prompt construction: assemble top passages with provenance and craft a generation prompt/system message that bounds the model (instructions to cite only retrieved content, refuse hallucination, and respect access controls). Design system prompts carefully, and consider deterministic mitigations where possible. (msrc.microsoft.com)
-
Generation and post-processing: call the LLM with a context window that fits the model and concatenated passages, then apply output filters (safety, PII removal) and attach provenance in the response. Implement deterministic blocking for high-risk outputs if necessary. (msrc.microsoft.com)
-
Feedback capture and indexing updates: record which passages were returned and used; collect human feedback or signal-based feedback to inform retriever tuning and re-index incremental content. Systematic logging is critical for monitoring and offline evaluation. (deepset.ai)
Design choices and trade-offs
Key dimensions where engineers must choose deliberately include retriever type, vector store, chunking strategy, reranking, model placement, and governance controls. Each decision has operational costs and quality impacts.
-
Vector store: managed (Pinecone, Milvus Cloud, Weaviate Cloud) reduces operational load and accelerates delivery; self-hosted stores (Milvus, Weaviate) provide control for compliance but increase DevOps work. Assess data residency, throughput, and expected vector counts before committing. (antalyze.ai)
-
Retriever architecture: dense retrievers require compute for embeddings at query time but provide semantic matching; keyword retrievers are cheap and deterministic. Hybrid retrieval is often a pragmatic production choice to balance recall, precision, and cost. (haystack.deepset.ai)
-
Chunking granularity: smaller chunks raise index size and increase recall but can fracture context; larger chunks reduce index size but can dilute relevance. Match chunk size to the types of questions you expect and the LLM context budget. (deepset.ai)
-
Reranking: cross-encoder rerankers (more accurate) add latency and GPU/CPU costs; bi-encoder re-ranking is faster but less precise. Use a two-stage approach: fast candidate retrieval then an expensive reranker when latency budget allows. (haystack.deepset.ai)
-
Model strategy: hosted API models reduce maintenance but introduce vendor constraints and data flow considerations; self-hosted open models provide control over data residency and fine-tuning but increase ops. Document retention, logging, and contractual terms with model providers are part of this trade-off. (llamaindex.ai)
-
Security and prompt injection: RAG systems are exposed to untrusted content (documents, web pages, user uploads). Defend using hardened system prompts, input sanitization, detection classifiers, and architectural controls that limit model ability to leak sensitive data. Microsoft recommends defense-in-depth—prevention, detection, and impact mitigation—and offers detection tools and design patterns. Recognize that deterministic detection is still an open research area; apply layered mitigations. (msrc.microsoft.com)
Common implementation mistakes
-
Ignoring provenance and metadata: not storing document IDs, source timestamps, and causal links between responses and retrieved passages undermines auditing and increases trust issues. Capture provenance at ingestion and attach it to answers. (deepset.ai)
-
Underindexing or overchunking data: indexing only part of a dataset or using inconsistent chunking leads to coverage gaps or massively inflated vector stores. Define chunking rules and validate coverage with queries representative of expected workloads. (haystack.deepset.ai)
-
No access controls on retrieval: exposing sensitive documents via an unconstrained retriever is a frequent data-leakage pathway. Integrate attribute/role-based filtering into the retrieval step or post-retrieval filters. (msrc.microsoft.com)
-
Treating indexing as a one-off job: production content changes—streams, daily batches, and deletions must be handled. Plan for incremental indexing, soft-deletes, and re-embedding strategies to keep the index current. (haystack.deepset.ai)
-
Over-reliance on LLM hallucinations: failing to use retrieved passages as grounded context and not enforcing citation policies leads to plausible-sounding but incorrect answers. Force the model to reference retrieved content and implement QA checks when answers make factual claims. (arxiv.org)
Testing, evaluation, and monitoring
RAG systems require both retrieval and generation evaluation. Treat these as separate but connected concerns.
-
Retrieval metrics: measure recall@k, MRR (mean reciprocal rank), and precision at k on held-out query sets to quantify whether relevant passages appear in candidates. Evaluate reranker quality separately with pairwise or ranking metrics. These are standard information-retrieval metrics and should be part of CI tests for retriever changes. (arxiv.org)
-
Generation metrics: beyond BLEU/ROUGE, use factuality checks and human evaluations to measure hallucinations. Where possible, create automated checks that compare facts in generated text against retrieved passages (claim–evidence matching) and flag conflicts for human review. (arxiv.org)
-
End-to-end user metrics: capture task completion, user-reported correctness, escalation rates, and re-query frequency. Instrument which passages were retrieved for each answer so you can do root-cause analysis when answers are wrong. (deepset.ai)
-
Operational monitoring: track latency p95/p99, vector DB health (storage, node utilization), embedding pipeline lag, and model error rates. Production guides recommend separating indexing and query SLIs to set proper SLOs and autoscaling policies. (haystack.deepset.ai)
-
Security monitoring: detect prompt-injection patterns and anomalous retrievals. Use classifier-based detectors and gating rules to reduce successful prompt-injection exploitation; but maintain defense-in-depth because detection is probabilistic. Microsoft documents defense-in-depth patterns and tooling for prompt-injection mitigation. (msrc.microsoft.com)
When certain aspects are still research-level (for example, deterministic detection of all prompt injections), note that the state-of-the-art is evolving and that you should design systems to fail safely—limit capability and minimize blast radius until mitigations mature. (msrc.microsoft.com)
“This article is for informational purposes and does not constitute security or legal advice.”
FAQ
What is RAG in Production and when should I use it?
RAG in Production refers to deploying retrieval-augmented generation systems that combine an external knowledge store with a generative model. Use RAG when you need updatable knowledge, provenance for answers, or when the domain is too large or dynamic for a static fine-tuned model to cover. The original RAG paper demonstrated improved factuality on knowledge-intensive tasks. (arxiv.org)
How do I choose a vector database for production?
Choose based on scale, operational expertise, compliance needs, and time-to-market. Managed services like Pinecone speed delivery and reduce ops, while self-hosted Milvus or Weaviate provide more control and on-prem options. Evaluate expected vector counts, query latency SLAs, and data residency requirements before committing. Industry comparisons and vendor docs provide practical guidance. (antalyze.ai)
How do I defend a RAG system from prompt injection and data exfiltration?
Use a defense-in-depth strategy: hardened system prompts, input sanitization, classifier-based detection, access controls and deterministic architectural patterns that limit LLM ability to access or transmit high-risk data. Microsoft recommends prevention, detection, and impact mitigation; detection is improving but is not perfect, so design for minimal blast radius. (msrc.microsoft.com)
Can I replace fine-tuning with RAG?
RAG and fine-tuning solve different problems. RAG is ideal for dynamic, large-scale knowledge that must be updated without retraining; fine-tuning can be better for task-specific behavioral shaping or when you require consistent, low-latency on-device inference. Many production systems use a hybrid: fine-tune for behavior+safety and use RAG to supply current facts. If uncertain for your use case, run small experiments comparing both approaches on your evaluation set. (arxiv.org)
How should I test and monitor RAG quality in production?
Test retrieval and generation separately: use IR metrics (recall@k, MRR) for retrieval, factuality and human evaluations for generation, and end-to-end SLIs for user outcomes. Log retrieval context for each answer to enable post-mortem analysis and model improvements. Use synthetic adversarial inputs and prompt-injection corpora during testing to validate defenses. (arxiv.org)
I focus on the engineering side of AI: how to design, ship, and operate LLM systems in the real world. I write about infrastructure, RAG, fine-tuning, evaluation, and cost–performance trade-offs, with an emphasis on turning technical decisions into reliable, scalable outcomes.